可视化练习总结
4.1新建Flask可视化项目
ViewData
├── app/
│ ├── models/ # 数据库映射类
│ │ └── __init__.py
│ ├── views/ # SQLAlchemy语法数据库访问类
│ │ ├── __init__.py
│ │ └── main.py
│ ├── templates/ # 模板
│ │ ├── main/ # 存放html前端页面
│ │ │ └── echarts.html
│ │ └── errors/
│ │ └── 404.html
│ ├── static/ # 静态资源
│ │ └── js/
│ ├── __init__.py # flask的初始化类
│ ├── config.py
│ └── extensions.py # 扩展,导入flask相关模块
├── manage.py
__init__.py 的作用是让一个呈结构化分布(以文件夹形式组织)的代码文件夹变成可以被导入import的软件包。
4.2新建 app/__init__.py
新建flask的初始化类,自定义函数def create_app(config_name)封装一个方法,专门用于创建Flask实例;自定义函数def config_errorhandler(app)编写访问失败之后的404页面的跳转设置。
app/__init__.py
# 封装一个方法,专门用于创建Flask实例
def create_app(config_name): # development
# 创建应用实例
app = Flask(__name__)
# 初始化配置
app.config.from_object(config.get(config_name) or config['default'])
# 调用初始化函数
config[config_name].init_app(app)
# 配置扩展 函数位置 app/ extensions.py
config_extensions(app)
# 配置蓝本
config_blueprint(app)
# 错误页面定制
config_errorhandler(app)
# 返回应用实例
return app
# 访问失败之后的404页面的跳转设置
def config_errorhandler(app):
# 如果在蓝本定制,只针对本蓝本的错误有效,
# 可以使用app_errorhandler定制全局有效的错误显示
@app.errorhandler(404)
def page_not_found(e):
return render_template('errors/404.html')
4.3新建app/config.py
新建flask连接数据库的配置类,将flask框架连接数据库的配置编写成函数,包括数据库的ip、端口、用户名、密码等。
import os
base_dir = os.path.abspath(os.path.dirname(__file__))
# os.path.abspath 返回绝对路径
# os.path.dirname(__file__) 去掉文件名,返回目录
# 通用配置
# 类中的配置项必须是大写的,否则读取配置失败
class Config:
# 秘钥
SECRET_KEY = os.environ.get('SECRET_KEY') or '123456'
# 没有设置secret_key,可能报Must provide secret_key to use csrf错误提醒
# Session, Cookies以及一些第三方扩展都会用到SECRET_KEY值
# 有些字符不宜明文写进代码里,比如数据库密码,个人账户密码,如果写进自己本机的环境变量里,程序用的时候通过os.environ.get()取出来就行了。这样开发人员本机测试的时候用的是自己本机的一套密码,生产环境部署的时候,用的是公司的公共账号和密码,这样就能增加安全性。os.environ是一个字典,是环境变量的字典。"SECRET_KEY"是这个字典里的一个键,如果有这个键,返回对应的值,如果没有,则返回none
# 数据库
SQLALCHEMY_COMMIT_ON_TEARDOWN = True # 每次请求结束后都会自动提交数据库中的变动。
SQLALCHEMY_TRACK_MODIFICATIONS = False # 动态追踪修改设置,如未设置只会提示警告, 不建议开启
# 额外的初始化操作,即使什么内容都没有写,也是有意义的
@staticmethod
def init_app(app):
pass
# 开发环境 语法:mysql+pymysql://用户名:密码@ip:端口/数据库名
class DevelopmentConfig(Config):
SQLALCHEMY_DATABASE_URI = 'mysql+pymysql://root:passwd@localhost:3306/visiondata'
# 测试环境
class TestingConfig(Config):
SQLALCHEMY_DATABASE_URI = 'mysql+pymysql://root:passwd@localhost:3306/visiondata'
# 生产环境
class ProductionConfig(Config):
SQLALCHEMY_DATABASE_URI = 'mysql+pymysql://root:passwd@localhost:3306/visiondata'
# 配置字典, 导入子类配置
config = {
'development': DevelopmentConfig,
'testing': TestingConfig,
'production': ProductionConfig,
'default': DevelopmentConfig
}
SQLALCHEMY 可配置项:
| 名字 | 备注 |
|---|---|
| SQLALCHEMY_DATABASE_URI | 用于连接的数据库 URI 。例如:mysql+pymysql://root:passwd@localhost:3306/visiondata |
| SQLALCHEMY_BINDS | 一个映射 binds 到连接 URI 的字典。 |
| SQLALCHEMY_ECHO | 如果设置为Ture, SQLAlchemy 会记录所有 发给 stderr 的语句,这对调试有用。(打印sql语句) |
| SQLALCHEMY_RECORD_QUERIES | 可以用于显式地禁用或启用查询记录。查询记录 在调试或测试模式自动启用。更多信息见get_debug_queries()。 |
| SQLALCHEMY_NATIVE_UNICODE | 可以用于显式禁用原生 unicode 支持。当使用 不合适的指定无编码的数据库默认值时,这对于 一些数据库适配器是必须的(比如 Ubuntu 上 某些版本的 PostgreSQL )。 |
| SQLALCHEMY_POOL_SIZE | 数据库连接池的大小。默认是引擎默认值(通常 是 5 ) |
| SQLALCHEMY_POOL_TIMEOUT | 设定连接池的连接超时时间。默认是 10 。 |
| SQLALCHEMY_POOL_RECYCLE | 多少秒后自动回收连接。这对 MySQL 是必要的, 它默认移除闲置多于 8 小时的连接。注意如果 使用了 MySQL , Flask-SQLALchemy 自动设定 这个值为 2 小时。 |
| SQLALCHEMY_COMMIT | 设置每次请求结束后会自动提交数据库的改动 |
| _ON_TEARDOWN |
Flask app.config 配置总结:
原理如下:
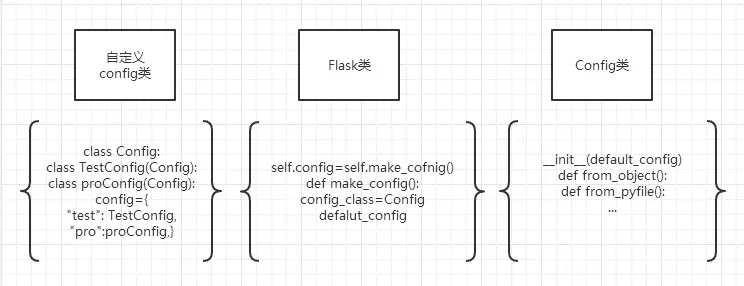
1、通过调用自定义config.py文件中config字典,可以得到一个类,这个类里面定义的都是类变量,这些变量就是自定义的一些配置项。
# 直接操作config的字典对象
app.config["DEBUG"] = True
# config字典内操作
class Config:
DEBUG = True
2、利用Flask类,实例app,并把自定义配置传进去。
# __name__是本文件名字,
# Flask类里面,会根据此名字,找到app所在目录,即默认为根目录。
app = Flask(__name__)
app.config.from_object(config['default'])
3、配置原理:
自定义配置类给到app.config。 app.config 来自于 self.make_config() self.make_config() 返回的值是 config_class() config_class 就是Config类。 config_class(),是config加个括号,其实就是Config()
可以看出:app.config,就是Config()
之所以要在中间加一些方法,如mke_config(),是为了给Config()添加一些默认值。 例如:根目录root_path、默认配置self.default_config等。 如下:
def make_config(self, instance_relative=False):
root_path = self.root_path
if instance_relative:
root_path = self.instance_path
return self.config_class(root_path, self.default_config)
其实,在写到app.config时,就已经创建了一个带默认配置项的Config()实例。 Config类有很多方法可以修改默认配置和添加新配置。如from_object()
当写到 app.config.from_object(config),其实就是对默认配置的修改和添加。
4.4新建app/extensions.py(扩展)
导入flask相关模块,创建SQLAlchemy对象并初始化Bootstrap。自定义函数def config_extensions(app)完成SQLAlchemy和Bootstrap的初始化
# 导入类库
from flask_bootstrap import Bootstrap
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate
# Flask-Migrate是用于处理SQLAlchemy 数据库迁移的扩展工具。当Model出现变更的时候,通过migrate去管理数据库变更。修改数据库不会直接手动的去修改,而是去修改ORM对应的模型,然后再把模型映射到数据库中。
from flask_moment import Moment
# Flask-Moment 用来处理时间日期等信息。用这个模块主要是考虑到两点,第一是为了让不同时区的用户看到的都是各自时区的实际时间,而不是服务器所在地的时间。第二是对于一些时间间隔的处理,如果要手动处理很麻烦,如果有模块就很好了。
# 创建对象
bootstrap = Bootstrap()
db = SQLAlchemy()
moment = Moment()
migrate = Migrate(db=db) # 第一个参数是Flask的实例,第二个参数是Sqlalchemy数据库实例
# 初始化
def config_extensions(app):
bootstrap.init_app(app)
db.init_app(app)
moment.init_app(app)
migrate.init_app(app)
4.5新建app/models/表名.py
编写flask的数据库表的映射类,每个表格对应一个文件,映射类命名与表名一致。
# app/models/avg_money_bigdata.py
class AvgMoneyBigData(db.Model):
__tablename__ = 'avg_money_bigdata'
id = db.Column(db.Integer, primary_key=True)
city = db.Column(db.String(255))
avg_money = db.Column(db.String(255))
# app/models/avg_money_city.py
class AvgMoneyCity(db.Model):
__tablename__ = "avg_money_city"
id = db.Column(db.Integer, primary_key=True)
city = db.Column(db.String(255))
avg_money = db.Column(db.String(255))
def __repr__(self):
return 'Id: %d , City: %s ,Avg_money: %s' %(self.id, self.city, self.avg_money)
# app/models/bigdata_work.py
class BigDataWork(db.Model):
__tablename__ = 'bigdata_work'
id = db.Column(db.Integer, primary_key=True)
job_name = db.Column(db.String(255))
company_name = db.Column(db.String(255))
city = db.Column(db.String(255))
job_require = db.Column(db.Text)
recruit_number = db.Column(db.String(255))
money = db.Column(db.String(255))
skill_require = db.Column(db.String(255))
release_date = db.Column(db.String(255))
sex = db.Column(db.String(255))
company_detail = db.Column(db.String(255))
education = db.Column(db.String(255))
# app/models/hot_work.py
class HotWork(db.Model):
__tablename__ = 'hot_work'
id = db.Column(db.Integer, primary_key=True)
job_name = db.Column(db.String(255))
job_number = db.Column(db.Integer)
常用的SQLAlchemy字段类型
| 类型名 | python中类型 | 说明 |
|---|---|---|
| Integer | int | 普通整数,一般是32位 |
| SmallInteger | int | 取值范围小的整数,一般是16位 |
| BigInteger | int或long | 不限制精度的整数 |
| Float | float | 浮点数 |
| Numeric | decimal.Decimal | 普通整数,一般是32位 |
| String | str | 变长字符串 |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode | unicode | 变长Unicode字符串 |
| UnicodeText | unicode | 变长Unicode字符串,对较长或不限长度的字符串做了优化 |
| Boolean | bool | 布尔值 |
| Date | datetime.date | 时间 |
| Time | datetime.datetime | 日期和时间 |
| LargeBinary | str | 二进制文件 |
常用的SQLAlchemy列选项
| 选项名 | 说明 |
|---|---|
| primary_key | 如果为True,代表表的主键 |
| unique | 如果为True,代表这列不允许出现重复的值 |
| index | 如果为True,为这列创建索引,提高查询效率 |
| nullable | 如果为True,允许有空值,如果为False,不允许有空值 |
| default | 为这列定义默认值 |
常用的SQLAlchemy关系选项
| 选项名 | 说明 |
|---|---|
| backref | 在关系的另一模型中添加反向引用 |
| primary join | 明确指定两个模型之间使用的联结条件 |
| uselist | 如果为False,不使用列表,而使用标量值 |
| order_by | 指定关系中记录的排序方式 |
| secondary | 指定多对多中记录的排序方式 |
| secondary join | 在SQLAlchemy中无法自行决定时,指定多对多关系中的二级联结条件 |
4.6新建app/models/init.py
编写flask的访问数据库的初始化文件,导入数据库映射表类。
from app.extensions import db
from .hot_work import HotWork
from .bigdata_work import BigDataWork
from .avg_money_city import AvgMoneyCity
from .avg_money_bigdata import AvgMoneyBigData
4.7新建app/static/js
将html前段需要用到的js工具包存放在js文件夹下。
4.8新建ViewData/mamage.py
新建flask启动类,创建flask实例和数据库迁移命令,以及程序的入口。
import os
from app import create_app
from flask_script import Manager, Server
from flask_migrate import MigrateCommand
# migrate的作用就是在数据库字段改变时不用drop表直接做更新操作
# 获取配置
config_name = os.environ.get('FLASK_CONFIG') or 'default'
# os模块获取环境变量的一个方法
# 创建Flask实例
app = create_app(config_name)
# 创建命令行启动控制对象
manager = Manager(app)
#三种方法创建命令,即创建Command子类、使用@command修饰符、使用@option修饰符;
# Command子类必须定义一个run方法
manager.add_command("runserver", Server(use_debugger=True))
# 添加数据库迁移命令
manager.add_command('db', MigrateCommand)
# 启动项目
if __name__ == '__main__':
# 调用manager.run()启动Manager实例接收命令行中的命令
manager.run()
Manager类追踪所有在命令行中调用的命令和处理过程的调用运行情况;
Manager只有一个参数——Flask实例,也可以是一个函数或其他的返回Flask实例;
三种方法创建命令,即创建Command子类、使用@command修饰符、使用@option修饰符:
from flask_script import Manager,Server
from flask_script import Command
...
manager = Manager(app)
# 第一种——创建Command子类
class Hello(Command):
'hello world'
def run(self):
print 'hello world'
# 自定义命令一:
manager.add_command('hello', Hello())
# 自定义命令二:
manager.add_command("runserver", Server()) #命令是runserver
'''
执行如下命令:
python manager.py hello
> hello world
python manager.py runserver
> hello world
'''
# 第二种——使用Command实例的@command修饰符
# 运行方式和Command类创建的运行方式相同
@manager.command
def hello():
'hello world'
print 'hello world'
#第三种——使用Command实例的@option修饰符(复杂情况下使用)
@manager.option('-n', '--name', dest='name', help='Your name', default='world')
#命令既可以用-n,也可以用--name,dest="name"用户输入的命令的名字作为参数传给了函数中的name
@manager.option('-u', '--url', dest='url', default='www.abc.com')
#命令既可以用-u,也可以用--url,dest="url"用户输入的命令的url作为参数传给了函数中的url
def hello(name, url):
'hello world or hello <setting name>'
print 'hello', name
print url
'''
运行方式如下:
python manager.py hello
>hello world
>www.123.com
python manager.py hello -n 111 -u www.111.com
> hello 111
>www.111.com
python manager.py hello -name 123 -url www.123.com
> hello 123
>www.123.com
'''
if __name__ == '__main__':
manager.run()
4.9新建app/views/__init__.py
新建flask的蓝本配置初始化类,进行蓝本的配置,自定义函数def config_blueprint(app)以及封装函数完成蓝本的注册。
from .main import main
# 蓝本配置
DEFAULT_BLUEPRINT = (
# 蓝本,前缀
(main, ''),
)
# 封装函数,完成蓝本注册
def config_blueprint(app):
for blueprint, prefix in DEFAULT_BLUEPRINT:
app.register_blueprint(blueprint, url_prefix=prefix)
Blueprint具有如下属性:
- 一个应用可以具有多个Blueprint
- 可以将一个Blueprint注册到任何一个未使用的URL下比如 “/”、“/sample”或者子域名
- 在一个应用中,一个模块可以注册多次
- Blueprint可以单独具有自己的模板、静态文件或者其它的通用操作方法,它并不是必须要实现应用的视图和函数的
- 在一个应用初始化时,就应该要注册需要使用的Blueprint
蓝图使用可以分为三个步骤
1,创建一个蓝图对象
`admin``=``Blueprint(``'admin'``,__name__) `
2,在这个蓝图对象上进行操作,注册路由,指定静态文件夹,注册模版过滤器
`@admin``.route(``'/'``)``def` `admin_home():`` ``return` `'admin_home'`
3,在应用对象上注册这个蓝图对象
`app.register_blueprint(admin,url\_prefix``=``'/admin'``)`
当这个应用启动后,通过/main/可以访问到蓝图中定义的视图函数
运行机制
- 蓝图是保存了一组将来可以在应用对象上执行的操作,注册路由就是一种操作
- 当在应用对象上调用 route 装饰器注册路由时,这个操作将修改对象的url_map路由表
- 然而,蓝图对象根本没有路由表,当我们在蓝图对象上调用route装饰器注册路由时,它只是在内部的一个延迟操作记录列表defered_functions中添加了一个项
- 当执行应用对象的 register_blueprint() 方法时,应用对象将从蓝图对象的 defered_functions 列表中取出每一项,并以自身作为参数执行该匿名函数,即调用应用对象的 add_url_rule() 方法,这将真正的修改应用对象的路由表。
蓝图的url前缀
- 当我们在应用对象上注册一个蓝图时,可以指定一个url_prefix关键字参数(这个参数默认是/)
- 在应用最终的路由表 url_map中,在蓝图上注册的路由URL自动被加上了这个前缀,这个可以保证在多个蓝图中使用相同的URL规则而不会最终引起冲突,只要在注册蓝图时将不同的蓝图挂接到不同的自路径即可
4.10新建app/views的main.py
import json
from flask import Blueprint, render_template, jsonify
from app.models import HotWork, BigDataWork, AvgMoneyCity, AvgMoneyBigData
from app.extensions import db
from sqlalchemy import *
main = Blueprint('main', __name__) # 实例化路由
@main.route('/')
def index():
return render_template('/main/echarts.html') # 当url访问 / 直接跳转到主页
@main.route('/index/') # url访问 /index/ 跳转主页 调用display方法 将查询结果通过render_template()传入html页面
def display():
rs_ghw = get_hot_work()
rs_gbdw = get_big_data_work()
rs_gamc = get_avg_money_city()
rs_gamb = get_avg_money_BigData()
return render_template('/main/echarts.html', rs_ghw=rs_ghw, rs_gbdw=rs_gbdw, rs_gamc=rs_gamc, rs_gamb=rs_gamb)
#(1)根据数据库表格hotwork,分析并统计招聘数量最多的前十名热门职位,分别使用柱状图表达。
# 统计招聘数量最多的前十热门职位 获取结果:
def get_hot_work(): # 编写查询语句 返回前10条
# sql: select * from hot_work group by job_name limit 10
ghw_rs = HotWork.query.order_by(desc('job_number')).limit(10)
print(ghw_rs)
return ghw_rs
#(2)请根据指定表中的数据,统计出全国某些城市指定招聘岗位平均工资,通过南丁格尔玫瑰图进行呈现。
# 所有城市招聘数据的平均工资 获取结果
def get_avg_money_city():
# sql: select * from avg_money_city
gamc_rs = AvgMoneyCity.query.all()
print('所有城市招聘数据的平均工资 获取结果成功')
return gamc_rs
# “大数据”相关职位所有城市招聘数据的平均工资 获取结果
def get_avg_money_BigData():
# sql: select * from avg_money_big_data
gamb_rs = AvgMoneyBigData.query.all()
print('“大数据”相关职位所有城市招聘数据的平均工资 获取结果成功')
return gamb_rs
#(3)分析并统计招聘数量"大数据"相关职位招聘数量,分别使用柱状图表达,同时在网页后台输出相关数据打印语句。
# 对相同职位进行数量汇总,"大数据"相关职位招聘数量比较
def get_big_data_work():
# sql: select job_name,count(*) from bigdata_work where job_name like '%大数据%' GROUP BY job_name
gbdw_rs = db.session.query(BigDataWork.job_name, func.count('*').label('job_count'))\
.group_by(BigDataWork.job_name).order_by(desc('job_count')).all()
print('"大数据"相关职位招聘数量:' + str(gbdw_rs))
return gbdw_rs
操作数据库
- 创建表:db.create_all()
- 删除表: db.drop_all()
- 插入行: db.session.add() db.session.addAll([]) db.session.commit()
- 查询全部数据: User.query.all()
- 过滤查询: User.query.filter_by(id=id).first()
- join多表查询:User.query.filter_by(env_id=env_id,id=id).join(Environments,Variable.env_id == Environments.id).first_or_404()
- count返回数量: User.query.filter_by(id=id).count()
4.11新建app/templates/errors/404.html
编写url访问失败之后的提示页面。
...404...
4.12新建app/templates/main/echarts.html
编写js获取到flask传过来的数据,通过echarts组件进行结果的展示(包括css样式)。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>招聘信息统计</title>
<script type="text/javascript" src="/static/js/echarts.js"></script>
<script type="text/javascript" src="/static/js/jquery.min.js"></script>
<script type="text/javascript" src="/static/js/js2wordcloud.js"></script>
</head>
<style>
html , body , .content {
width:100%;
height:100%;
padding: 0;
margin: 0;
box-sizing: border-box;
background-color: #ccc;
}
.content {
padding: 40px;
}
.header {
height: 10%;
width: 100%;
font-size: 24px;
font-weight: 700;
line-height: 60px;
text-align: center;
}
.body {
height: 100%;
width: 100%;
text-align: center;
}
.chartBox {
width: 100%;
height: 60%;
margin-bottom:40px;
}
</style>
<body>
<div class="content">
<div class="header"></div>
<div class="body">
<div class="chartBox" id="hotWork"></div>
<div class="chartBox" id="bigDataWork"></div>
<div class="chartBox" id="pieAvgMoneyCity"></div>
</div>
</div>
</body>
<script>
//折线图 招聘数量最多的前十热门职位
var hotWork = echarts.init(document.getElementById('hotWork')); //获取div的id 实例化echarts组件
var data_name = [{% for r in rs_ghw %} "{{r.job_name}}", {% endfor %}] //将职位名job_name存放在一个数组中作为x轴数据
var data_y = [{% for r in rs_ghw %}"{{r.job_number}}",{% endfor %}] //将职位数量job_number存放在一个数组中作为y轴数据
console.log('十大热门职位:' + data_name);
console.log('数据分别为:' + data_y);
console.log('最大值: ' + Math.max.apply(null, data_y) + ', 最小值:' + Math.min.apply(null, data_y));
workOption = {
title: {
text: '职位分析', //主标题
subtext: ' ---10大热门职位分析', //副标题
x: '45%' //设置标题位置
},
xAxis: {
type: 'category',
name: '岗位名称',
data: data_name,
axisLabel : {
interval: 0,
rotate: "25" //x轴字体的旋转度
}
},
yAxis: {
name: '招聘数量',
type: 'value'
},
series: [{
data: data_y,
type: 'line', //设置图形为折线图
label: {
normal: {
show: true,
position: 'top' //折线图顶部显示对应的x轴数值
}
}
}]
};
hotWork.setOption(workOption); //设置echarts的option参数 加载并显示图形
//南丁格尔玫瑰图
var pieAvgMoneyCity = echarts.init(document.getElementById('pieAvgMoneyCity'));
var city = [{% for r in rs_gamc %}"{{r.city}}",{% endfor %}]
var avg_money_pie_city = [{% for r in rs_gamc %}{value:"{{r.avg_money}}", name:"{{r.city}}"},{% endfor %}]
var avg_money_pie_bigdata = [{% for r in rs_gamb %}{value:"{{r.avg_money}}", name:"{{r.city}}"},{% endfor %}]
var avg_money_city = [{% for r in rs_gamc %} "{{r.avg_money}}", {% endfor %}]
var avg_money_big_data = [{% for r in rs_gamb %}"{{r.avg_money}}",{% endfor %}]
var dataInt_city = [];
var dataInt_big_data = [];
dataInt_city.forEach(function(data){
avg_money_city.push(+parseInt(data)); ///遍历数组 将每个元素变成整型
});
dataInt_big_data.forEach(function(data){
avg_money_big_data.push(+parseInt(data)); ///遍历数组 将每个元素变成整型
});
console.log('所有城市平均薪资:' + city);
console.log('数据分别为:' + avg_money_city);
console.log("所有城市最大平均薪资为" + Math.max.apply(null, avg_money_city));
console.log("“大数据”相关职位城市招聘数据的平均工资" + city);
console.log('数据分别为:' + avg_money_big_data);
console.log("“大数据”相关职位最大平均薪资为" + Math.max.apply(null, avg_money_big_data));
pieAvgMoneyCityOption = {
title : {
text: '所有城市招聘数据的平均工资 vs “大数据”相关职位所有城市招聘数据的平均工资',
subtext: '南丁格尔玫瑰图',
x:'center'
},
tooltip : {
trigger: 'item',
formatter: "{b}:{c}({d}%)" //当鼠标移动到图形 显示数据(格式): 佛山(1111) 10%
},
legend: {
x : 'center',
y : 'bottom',
data:city
},
color:[
'#C1232B','#B5C334','#FCCE10','#E87C25','#27727B',
'#668ffe','#00ca54','#00dbfa','#f3006a','#60C0DD',
'#d714b7','#84433c','#f490f3','#000000','#26C0C0'],
series : [
{
type:'pie',
radius : [20, 110], //图像的大小
center : ['25%', '50%'], //图形的位置
roseType : 'radius', //南丁格尔玫瑰图的参数
data:avg_money_pie_city
},
{
type:'pie',
radius : [30, 110],
center : ['75%', '50%'],
roseType : 'area',
data:avg_money_pie_bigdata
}
]
};
pieAvgMoneyCity.setOption(pieAvgMoneyCityOption);
//柱状图 "大数据"相关职位招聘数量
var bigDataWork = echarts.init(document.getElementById('bigDataWork'));
var job_name = [{% for r in rs_gbdw %} "{{r.job_name}}", {% endfor %}]
var quantity = [{% for r in rs_gbdw %}"{{r.job_count}}",{% endfor %}] // 获取元组中的第二个元素('AI大数据工程师', 1095)
console.log('招聘职位: ' + job_name);
console.log('对应职位招聘数量: ' + quantity);
console.log('岗位需求量最大: ' + Math.max.apply(null, quantity) + ', 岗位需求量最少:' + Math.min.apply(null, quantity));
bigdataworkOption = {
title: {
text: '大数据相关职位招聘数量',
subtext: ' ----职位招聘对比',
x: '45%',
//modified 0523
textStyle:{
//文字颜色
color:'#f30008',
//字体风格,'normal','italic','oblique'
fontStyle:'oblique',
//字体粗细 'normal','bold','bolder','lighter',100 | 200 | 300 | 400...
fontWeight:'bold',
//字体系列
fontFamily:'FangSong'
//fontFamily: 'KaiTi'
//字体大小
//fontSize:18
}
//modified end
},
xAxis: {
type: 'category',
name: '职位名称',
data: job_name,
axisLabel : {
interval: 0,
rotate: "15" //x轴字体的旋转度
}
},
yAxis: {
type: 'value',
name: '招聘数量'
},
series: [{
data: quantity,
type: 'bar',
label: {
normal: {
show: true,
position: 'top'
}
},
//modified0523
itemStyle: {
normal: {color: 'black'}
}
//modified end
}]
};
bigDataWork.setOption(bigdataworkOption);
</script>
</html>
4.13运行Flask程序查看结果
(1)分析并统计招聘数量最多的前十名热门职位,分别使用折线图表达
(2)分析并统计招聘数量"大数据"相关职位招聘数量,分别使用柱状图表达。
(3)统计出全国某些城市指定招聘岗位平均工资,通过南丁格尔玫瑰图进行呈现。
Echarts 可视化
基本名词
| 名词 | 描述 |
|---|---|
| chart | 是指一个完整的图表,如折线图,饼图等“基本”图表类型或由基本图表组合而成的“混搭”图表,可能包括坐标轴、图例等 |
| axis | 直角坐标系中的一个坐标轴,坐标轴可分为类目轴和数值轴 |
| xAxis | 直角坐标系中的横轴,通常并默认为类目轴 |
| yAxis | 直角坐标系中的纵轴,通常并默认为数值轴 |
| grid | 直角坐标系中除坐标轴外的绘图网格 |
| legend | 图例,表述数据和图形的关联 |
| dataRange | 值域选择,常用于展现地域数据时选择值域范围 |
| dataZoom | 数据区域缩放,常用于展现大数据时选择可视范围 |
| toolbox | 辅助工具箱,辅助功能,如添加标线,框选缩放等 |
| tooltip | 气泡提示框,常用于展现更详细的数据 |
| timeline | 时间轴,常用于展现同一组数据在时间维度上的多份数据 |
| series | 数据系列,一个图表可能包含多个系列,每一个系列可能包含多个数据 |
图表名词
| 名词 | 描述 |
|---|---|
| line | 折线图,堆积折线图,区域图,堆积区域图。 |
| bar | 柱形图(纵向),堆积柱形图,条形图(横向),堆积条形图。 |
| scatter | 散点图,气泡图。散点图至少需要横纵两个数据,更高维度数据加入时可以映射为颜色或大小,当映射到大小时则为气泡图 |
| k | K线图,蜡烛图。常用于展现股票交易数据。 |
| pie | 饼图,圆环图。饼图支持两种(半径、面积)南丁格尔玫瑰图模式。 |
| radar | 雷达图,填充雷达图。高维度数据展现的常用图表。 |
| chord | 和弦图。常用于展现关系数据,外层为圆环图,可体现数据占比关系,内层为各个扇形间相互连接的弦,可体现关系数据 |
| force | 力导布局图。常用于展现复杂关系网络聚类布局。 |
| map | 地图。内置世界地图、中国及中国34个省市自治区地图数据、可通过标准GeoJson扩展地图类型。支持svg扩展类地图应用,如室内地图、运动场、物件构造等。 |
Jinja2 模板引擎
注释
- 使用 {# #} 进行注释
{# 这是注释 #}
变量代码块
{{}}来表示变量名,这种{{}} 语法叫做变量代码块
{{ post.title }}
Jinja2 模版中的变量代码块可以是任意Python类型或者对象,只要它能够被Python的str()方法转换为一个字符串就可以,比如,可以通过下面的方式显示一个字典或者列表中的某个元素:
{{your_dict['key']}}
{{your_list[0]}}
控制代码块
- 用 {%%} 定义的控制代码块,可以实现一些语言层次的功能,比如循环或者if语句
{% if user %}
{{ user }}
{% else %}
hello!
{% for index in indexs %}
{{ index }}
{% endfor %}
过滤器
过滤器的本质就是函数。有时候我们不仅仅只是需要输出变量的值,我们还需要修改变量的显示,甚至格式化、运算等等,而在模板中是不能直接调用 Python 中的某些方法,那么这就用到了过滤器。
使用方式:
- 过滤器的使用方式为:变量名 | 过滤器。
{{variable | filter_name(*args)}}
- 如果没有任何参数传给过滤器,则可以把括号省略掉
{{variable | filter_name}}
- 如:``,这个过滤器的作用:把变量variable 的值的首字母转换为大写,其他字母转换为小写
链式调用
在 jinja2 中,过滤器是可以支持链式调用的,示例如下:
{{ "hello world" | reverse | upper }}
常见内建过滤器
字符串操作
- safe:禁用转义
<p>{{ '<em>hello</em>' | safe }}</p>
- capitalize:把变量值的首字母转成大写,其余字母转小写
<p>{{ 'hello' | capitalize }}</p>
- lower:把值转成小写
<p>{{ 'HELLO' | lower }}</p>
- upper:把值转成大写
<p>{{ 'hello' | upper }}</p>
- title:把值中的每个单词的首字母都转成大写
<p>{{ 'hello' | title }}</p>
- reverse:字符串反转
<p>{{ 'olleh' | reverse }}</p>
- format:格式化输出
<p>{{ '%s is %d' | format('name',17) }}</p>
- striptags:渲染之前把值中所有的HTML标签都删掉
<p>{{ '<em>hello</em>' | striptags }}</p>
- truncate: 字符串截断
<p>{{ 'hello every one' | truncate(9)}}</p>
列表操作
- first:取第一个元素
<p>{{ [1,2,3,4,5,6] | first }}</p>
- last:取最后一个元素
<p>{{ [1,2,3,4,5,6] | last }}</p>
- length:获取列表长度
<p>{{ [1,2,3,4,5,6] | length }}</p>
- sum:列表求和
<p>{{ [1,2,3,4,5,6] | sum }}</p>
- sort:列表排序
<p>{{ [6,2,3,1,5,4] | sort }}</p>
语句块过滤
{% filter upper %}
一大堆文字
{% endfilter %}
Flask特有的变量和函数
你可以在自己的模板中访问一些Flask默认内置的函数和对象
config
你可以从模板中直接访问Flask当前的config对象:
{{ config.root_path }}
/Users/Andy/Desktop/Codes/flask_demo
request
就是flask中代表当前请求的request对象:
{{request.url}}
http://127.0.0.1:5000/
url_for()
url_for会根据传入的路由器函数名,返回该路由对应的URL,在模板中始终使用url_for()就可以安全的修改路由绑定的URL,则不比担心模板中渲染出错的链接:
url_for('hello_world')
/
如果我们定义的路由URL是带有参数的,则可以把它们作为关键字参数传入url_for(),Flask会把他们填充进最终生成的URL中:
{{ url_for('user', user_id=1)}}
/user/1
session
为Flask的session对象
{{ session.get('name') }}
g
应用上下文, 可以再一次请求中方便的进行属性值的传递
{{ g.age }}
get_flashed_messages()
这个函数会返回之前在flask中通过flash()传入的消息的列表,flash函数的作用很简单,可以把由Python字符串表示的消息加入一个消息队列中,再使用get_flashed_message()函数取出它们并消费掉:
{%for message in get_flashed_messages()%}
{{message}}
{%endfor%}
控制代码块
if语句
Jinja2 语法中的if语句跟 Python 中的 if 语句相似,后面的布尔值或返回布尔值的表达式将决定代码中的哪个流程会被执行:
{%if user.is_logged_in() %}
<a href='/logout'>Logout</a>
{% else %}
<a href='/login'>Login</a>
{% endif %}
过滤器可以被用在 if 语句中:
{% if comments | length > 0 %}
There are {{ comments | length }} comments
{% else %}
There are no comments
{% endif %}
循环
- 我们可以在 Jinja2 中使用循环来迭代任何列表或者生成器函数
{% for num in my_list %}
{% if num > 3 %}
{{ num }}
{% endif %} <br>
{% endfor %}
- 循环和if语句可以组合使用
{% for num in my_list if num > 3 %}
{{ num }} <br>
{% endfor %}
- 在一个 for 循环块中你可以访问这些特殊的变量:
| 变量 | 描述 |
|---|---|
| loop.index | 当前循环迭代的次数(从 1 开始) |
| loop.index0 | 当前循环迭代的次数(从 0 开始) |
| loop.revindex | 到循环结束需要迭代的次数(从 1 开始) |
| loop.revindex0 | 到循环结束需要迭代的次数(从 0 开始) |
| loop.first | 如果是第一次迭代,为 True 。 |
| loop.last | 如果是最后一次迭代,为 True 。 |
| loop.length | 序列中的项目数。 |
| loop.cycle | 在一串序列间期取值的辅助函数。见下面示例程序。 |
- 在循环内部,你可以使用一个叫做loop的特殊变量来获得关于for循环的一些信息
- 比如:要是我们想知道当前被迭代的元素序号,则可以使用loop变量的index属性,例如:
{% for num in my_list %}
{{ loop.index }} -
{% if num > 3 %}
{{ num }}
{% endif %} <br>
{% endfor %}
- 假设my_list=[1, 3, 5, 7, 9]会输出这样的结果
1-
2-
3-5
4-7
5-9
- cycle函数会在每次循环的时候,返回其参数中的下一个元素,可以拿上面的例子来说明:
{% for num in my_list %}
{{ loop.cycle('a', 'b') }} -
{{ num }} <br>
{% endfor %}
- 会输出这样的结果:
a-
b-
a-5
b-7
a-9
- 可以在循环的开始和结束位置放置一个
-号去除for循环不换行情况下产生的空格
{% for num in my_list -%}
{{ num }}
{%- endfor %}
模板代码复用
一. 继承
模板继承是为了重用模板中的公共内容。一般Web开发中,继承主要使用在网站的顶部菜单、底部。这些内容可以定义在父模板中,子模板直接继承,而不需要重复书写。
- 标签定义的内容
{% block top %} {% endblock %}
- 相当于在父模板中挖个坑,当子模板继承父模板时,可以进行填充。
- 子模板使用extends指令声明这个模板继承自哪个模板
- 父模板中定义的块在子模板中被重新定义,在子模板中调用父模板的内容可以使用super()
父模板
- base.html
{% block top %}
<h1>这是头部内容</h1>
{% endblock %}
{% block center %}
这是父类的中间的内容
{% endblock %}
{% block bottom %}
<h1>这是底部内容</h1>
{% endblock %}
子模板
- extends指令声明这个模板继承自哪
{% extends 'base.html' %}
{% block content %}
{{ super() }} <br>
需要填充的内容 <br>
{% endblock content %}
模板继承使用时注意点:
- 不支持多继承
- 为了便于阅读,在子模板中使用extends时,尽量写在模板的第一行。
- 不能在一个模板文件中定义多个相同名字的block标签。
- 当在页面中使用多个block标签时,建议给结束标签起个名字,当多个block嵌套时,阅读性更好。
二. 包含
Jinja2模板中,包含(Include)的功能是将另一个模板整个加载到当前模板中,并直接渲染。
- include的使用
{% include 'hello.html' %}
包含在使用时,如果包含的模板文件不存在时,程序会抛出TemplateNotFound异常,可以加上 ignore missing 关键字。如果包含的模板文件不存在,会忽略这条include语句。
- include的使用加上关键字ignore missing
{% include 'hello.html' ignore missing %}