Hadoop自定义计数器Counter
一:背景
Hadoop计数器的主要价值在于可以让开发人员以全局的视角来审查程序的运行情况,及时作出错误诊断并进行相应的处理,Hadoop内置了很多计数器,这些计数器大致可以分为三组:MapReduce相关的计数器、文件系统相关的计数器以及作业调度相关的计数器。我们可以通过Eclipse控制台的输出或者是web页面http://master:50030进行查看。
二:技术实现
除了内置计数器,Hadoop还提供了自定义计数器的功能,自定义计数器经常适用于的场景是统计无效记录或者是统计敏感词。
定义一个计数器有两种形式
\1.通过枚举类型进行定义:**
// 定义一个枚举,用于统计无效记录
enum ERRORCounter {
ERROR;
}
context.getCounter(ERRORCounter.ERROR).increment(1);
\2.动态声明计数器,不需要使用枚举**
context.getCounter(String groupName,String counterName)
在程序中自定义一个计数器,运行程序,控制台输出的结果如下图:
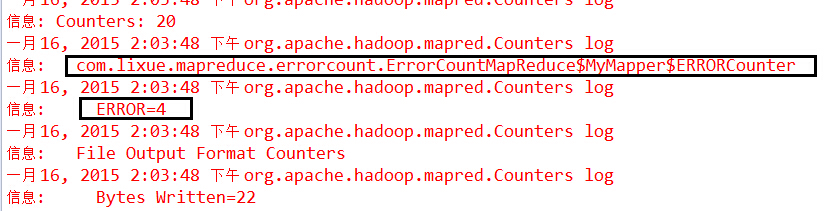
\注:通常情况下,我们自定义的计数器的名字会以:包名+类名+计数器名字的形式显示在控制台,有时候我们想显示的人性化一点即显示我们想要的计数器名称,解决方案是在该MapReduce程序同一个包下建立一个属性文件,文件的命名规则是:类内部类枚举.properties**
属性文件的内容如下:
#CounterGroupName 用来声明groupName的控制台显示信息
CounterGroupName=敏感词计数器
#枚举类型加.name用来声明counterName的控制台显示信息
ERROR.name=非法记录